Языки программирования – 13
В начале 90-х было две основные фирмы, которые производили компиляторы и прочее программное обеспечение для программистов. Это – Borland и Microsoft.
Точнее вначале это, по моему, был только Borland. Именно он выпустил самые популярные на тот момент Турбо-Си и Турбо-Паскаль (язык программирования, который проще Си и изначально был предназначен для обучения).
Потом появились Windows и визуальные среды программирования. Borland выпустил Borland C++ и Delphi (продолжение Паскаль). Microsoft выпустил Visual C++ и Visual Basic. Этот Basic стал вариантом упрощённого языка от Microsoft.
Одновременно с компиляторами языков появились свои форматы баз данных, ориентированных на работу с SQL строками. До этого были Dbase и Foxbase(?) – две оболочки для работы в базами в виде DBF файлов.
Borland придумал InterBase и файлы данных форматов FDB и GDB (так и не знаю, чем они отличаются). Первый MS SQL Server от Microsoft, который я помню был с номером 2000. Подозреваю, что InterBase появился раньше. До MS SQL Server можно было работать с базами формата MS Access. К этим базам можно было обращаться из клиентских приложений, но эти были просто открываемые файлы, а не нечто, обслуживаемое сервером.
Поскольку там было изначально две фирмы со своими форматами данных языки, которые они предлагали тоже были ориентированы на работу со своим типом данных. Borland больше ничего не выпустил. Но основанная масса например моих ровесников училась, когда Borland был сильнее Microsoft. Отсюда ползёт многое, от представлений о том, что лучше что хуже до уже привычек использовать это и только это. Переучиваться в любом деле сложно.
Что касается форматов FDB и GDB, придуманных Borland-ом под конец существования… Я так и не собралась аккуратно, с секундомером это проверить. Моё лично ощущение: это работает медленнее раз в 10. Есть среда (про ней ниже) доя работы с базами напрямую. Когда есть какой-то опыт, примерно представляешь сколько времени что потребует прикидывая сложность действий и размер базы. До встречи и InterBase я думала, что не существуют базы из которых сотню строк можно выбирать несколько секунд. Подробности сложны, потому не буду описывать что и как выбиралось. Это моё личное ощущение.
Но пусть люди работают именно на этом. И по психологическим причинам и потому, что обычно людей берут ковыряться в ранее написанных текстах а не писать что-то новое да ещё и на непривычном языке.
Ещё один пример, интересный тем, что он настоящий и показывает сразу многое. Имеется база данных в GDB формате. Я смотрю тексты программы и вижу, что там работа формально с SQL, но реально так, как это делалось с DВF файлами. Так можно писать, хотя это считается безграмотным с точки зрения обработки данных (той самой сборки на сервере и отправки клиенту уже собранного). Спрашиваю автора «Почему?». Ответ «Я так всегда писал». Ладно, его дело.
Но там случилось кое-что похуже. Видимо, с него хотели быстродействия. А быстродействия он дать не мог. Подозреваю, что с этим FDB-GDB происходит то, что и должно происходить с халтурой: оно сносно работает при малых объемах данных. На большие объёмы оно не рассчитано, т.е работает но очень(!) медленно. Т.е писать на этом можно если это домашняя бухгалтерия с 50 чеками на недельную закупку еды и 12 квитанциями на квартиру за год. Остальное не рекомендуется. Но пишут.
В прошлом году у меня возникла идея сделать пистолет, работающий на магнитах:
http://akostina76.ucoz.ru/blog/2016-02-22-2639
… Потом выяснилось, что нет таких магнитов, который могли бы обеспечить нужное ускорения. Предложенное невозможно просто по физическим законам. И я отбрасываю эту идею как бред. Но если у меня по каким-то причинам все ориентировано на GDB формат данных и продукцию Borland я буду пихать в это файл всё, что попадёт в руки. Итак, парень начал писать программу с большими объемами данных, засунул данные в GDB и понял, что это работает запредельно медленно. Тогда он сделал то, от чего у меня как человека начинавшего с DBF, волосы на голове немного зашевелились. Он начал динамически добавлять не строки и поля в таблицы базы данных. Видимо, так работало быстрое, т.е решение было найдено.
Объяснюсь, почему меня это так напугало. Напомню, что информация в DBF файле это последовательно записанные в него строки:
http://akostina76.ucoz.ru/blog/2016-10-04-3489
Если надо добавить поле (колонку) в DBF, то лучше сохранить копию а уже потом добавлять потому что если выключат электричество в момент добавления то пропадёт всё. В файл DBF ничего не добавляется. Создаются новый, пустой файл с новой структурой и в него копируются данные. Потом старый файл удаляется а новый переименовывается. Понятно что GDP устроен как-то сложнее, но вряд ли там данные храниться принципиально иначе и операция добавления/удаления полей скорее всего тоже очень тяжелая по количеству действий, хотя формально это не запрещено.
Кончилось тем, что когда с базой начали всерьёз работать она начала рассыпаться до невосстановимого состояния.
Формально база дынных к которой обращаются через SQL должна выполнять действия быстрее чем тексты программиста. Но возможно, что последнее творение Borland-а даже этого не делало. Потому работа с базой SQL в стиле работы с DBF (как делал привычный к ней программист) возможно тоже была правильным действием а не признаком замшелости.
Когда я писала про то, что на SQL «худо-бедно» перешли я имела в виду все эти вещи. И использование Interbase как хранилища информации. И программирование в SQL среде так, как это делали с DBF, т.е вытащили SQL строками все таблицы, а потом программными средствами что-то сделали.
Окно базы на MS SQL Server:

Слева – список объектов выбранной базы данных. Наиболее понятые из них – таблицы. Прямо из этой оболочки в окне можно написать SQL строку и выполнить её. Результат выполнения справа снизу. В данном случае это список строк таблицы.
Ещё в сервере для каждой базы есть (слева снизу) раздел «Программирование». Формально SQL интерпретирует строки в момент выполнения и только потом как-то выбирает данные. Но можно написать хранимую процедуру:

… на выполнения действий любой сложности и тогда в базе будет храниться уже скомпилированная функция, которой достаточно передать какие-то параметры.
Ещё есть мало описанные вещи, позволяющие ускорить работу на сервере. Явно в каком-то виде храниться сценарии выполнения частых запросов (т.е SQL строк, которые запускались и не были частью хранимой процедуры). Явно первый запуск выборки отрабатывает медленнее чем последующие, значит в каком-то виде что-то там внутри сохраняется и для таких строк.
1C начиная с версии 8.2 позволяет хранить базу в MS SQL Server:
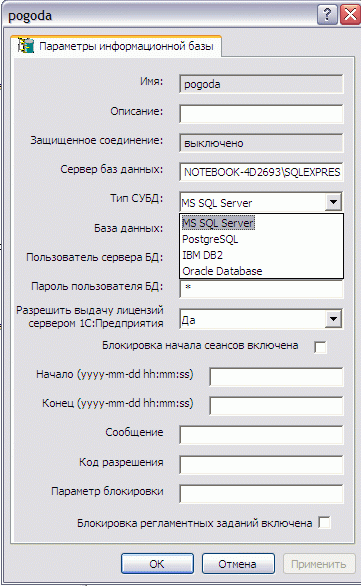
.. и ещё в трёх варрантах базы. Про Oracle уже сказано. Другие два не знаю. InterBase тут нет, видимо считается это не надо это использовать.
1Совцы немного жульничают когда говорят о возможностях. Вот стандартный вызов SQL строки из 1С:

Средствами 1С это будет переведено с русского на стандартный SQL SELECT и отправлено SQL Server-у. Ничего другого 1С не может, т.е использовать средства программирования SQL Server-а (те самые хранимые процедуры, например), отсюда нельзя. Но всё ускорение, которое даёт сервер на уровне предкомпиляции часто получаемых строк тут будет работать.
Сам по себе SQL Server (не 1С) позволяет подключать несколько баз и работать сразу со всеми этими данными. Имя базы указывается в SQL строке:

… т.е чтобы использовать данные из другой базы в той же SQL строке достаточно сослаться на таблицу той базы, указав полное её название (с названием базы).
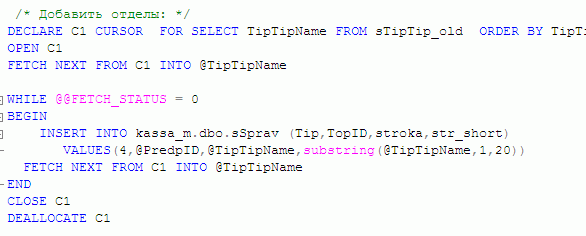
Хранимые процедуры позволяют работать не только с помощью вызов стандартных строк SQL (SELECT, INSERT, DELETE, UPDATE) но и обрабатывая выборку строк в цикле:
В локальной сети может быть сколько угодно SQL Server-ов расположенных на разных компьютерах. На всех этих серверах могут быть какие-то свои базы. Если SQL Server виден в сети, то информацию с него тоже можно брать, но строка выглядит немного сложнее:

В данном случае в сети есть сервер с именем SQL5601RCN. На нём есть база с именем local16.accdb. В ней есть таблица K_LSR, из которой выкачиваются данные.
Средствами SQL Serverа, инструментом под названием trigger можно сделать так, что при каком-то действии в одной базе будет происходить действие в другой базе. Например 1C не умеет работать сразу с несколькими базами, т.е в нем нельзя просто указать имя базы и таблицы куда надо что-то записать (точнее можно, но сложно). Пусть например офис работает с двумя базами. Первая - основная рабочая, вторая - отдельно для анализа информации с итогами. Пусть например в одной базе добавлен новый покупатель. Хорошо если сразу автоматически тот же покупатель появится и в справочнике покупателей второй базы. Точно также его название должно измениться если его изменили в какой-то из баз. Если это не делается автоматически это придётся делать вручную. Триггера позволяют повесить такие операции на сервер.
Можно подключить с серверу информацию в почти любом виде:

Можно хоть Excel-есовскую таблицу подключить, не говоря уж об DBF всяких. Можно даже FDB-GDB подключать если установлен специальный драйвер. Когда такой файл с информацией подключен к серверу к нему тоже можно откуда угодно обращаться в SQL строках, хранимых процедурах и прочем.
Т.е всё сделано для того чтобы информацию из самых разнообразных мест и форматов можно было собирать, считать на мощном сервере и передавать результат любому маломощному по вычислительным возможностям клиенту.
|




