Языки программирования – 16
В своё время мне задали простой вопрос: «Зачем нужен компьютер?». Я ответила: «Чтобы быстро искать и суммировать». Можно ещё добавить: «Чтобы печатать документы и убрать проблему плохого почерка».
Т.е компьютер это такой пустой «чёрный ящик». Если в нём вообще что-то появилось, то это было вызвано тем, что это кому-то потребовалось. Людям потребовалось искать и суммировать. Но чтобы была эта возможность в компьютере должна быть информация, по которой искать и которую суммировать. Так в компьютерах появились базы данных не потому, что они нужны пользователям а потому, что без них невозможно дать пользователям то, что им нужно. Т.е содержимое компьютеров в виде баз данных тоже в конечном счёте вызвано пожеланиям пользователей, но прямой связи тут нет.
Следующий уровень, который от пожеланий пользователей ещё дальше – чтобы в базе данных появилась информация нужна возможность её туда вводить. Точнее нужны возможность добавлять, изменять и удалять данные. Без этого просто ничего не может быть.
Это означает, что какой бы ни была программа, операции корректировки данных там будут. Не важно как называются кнопки, не важно на каком языке эти названия. Важно что в любом экране корректировки информации будут эти возможности добавления, удаления и корректировки в какому-то виде реализованные.
Документ в базе данных это не бумажка которая бродит по организации, а только её электронная копия. Точно также прочее внутренне устройство это своеобразная копия потребностей пользователей и технических решений, позволяющих дать пользователю желаемое.
Это не только с кнопками. В любой базе данных есть справочники с постоянной информацией и документы, фиксирующие происходящие события. Если я называю справочники справочниками, то я могу завести префикс «s» и названия типа sPokup для справочника покупателей. Если я по какой-то причине называю справочники классификаторами то будет например K_LS для справочника – классификатора лицевых счетов учреждений. Нечто с редко меняемой информацией, как его не назови, свойств своих не поменяет. Никакого общего языка нет. Обычно в каждом случае надо смотреть что и как называет конкретный программист. Немного выручает то, что разнообразных объектов как и действий не очень много.
А ещё там обычно некоторый бардак потому, что от этих названий ничего не зависит. Просто для примера:

Первая буква «d» означает «Документ» (dDocs, dFolder). Документ это всё, что имеет дату. Довольно часто информация документа записана в нескольких таблицах. Это сам список документов с датой и прочим содержимым заголовка и содержание документа, т.е строки накладной например. Здесь в названиях содержаний в конце «Cont» от content, наверное. Т.е dFolder – список папок, а dFolderCont – список документов, включённых в папки.
Экзотическое начало EDIT – таблицы с историй корректировки данных. Эти таблицы такие же по структуре как и рабочие таблицы базы данных, но в них добавлены поля «время корректировки», «имя пользователя», «действие» (I – insert,. D – delete, U – update), т.е при удалении например сюда сохраняется вся информация удалённой строки и если надо можно восстановить информацию. Часть названия после EDIT – название основной таблицы. Причина возникновения этих таблиц – ситуация. Мы как-то вечером в офисе проводили возврат шмотки, купленной по банковской карте… Потом с трудом вспомнили, что там вначале-то было.
grfPie – какой-то хлам от графика. По-моему тут нет никаких графиков, но проще оставить таблицу чем искать надо это или нет.
oTov – какие-то начальные остатки потому «o».
pKassa – планы поводок (в отличие от самих проводок dKassa)
Таблица s_tblProd – конкретный пример того, что такого уж стабильного почерка нет даже у одного человека. Обычно свои действия как-то синхронизируются с тем, что есть в конторе. Если тут у всех таблиц префикс «tbl», то мне-то какая разница? Пусть будет «tbl». Потом эти вещи могут переползать в другие базы, например если новая база импортирует информацию или полное название стало (в восприятии) целым словом. Так и возникло во-первых «s» потому, что здесь это справочник во-вторых tblProd потому что в какой-то старой базе была таблица именно с этим именем.
«s» - справочники, «t» - временные таблицы. Ещё внизу есть «u» - установки. Например uUser – настройки пользователей.
Но вообще-то всё это не имеет никакого значения. Можно хоть называть t1,t2,t3 и т.д. Потому что ориентировка идёт не по названию, которое кто-то помнит а по тому, что написано в программе. Именно туда надо войти по посмотреть какая конкретно хранимая процедура вызывается или из какой конкретно таблицы выбираются данные.
Не знаю, насколько хорошо показывать пример, уже ориентированных под штамповку… зато просто:
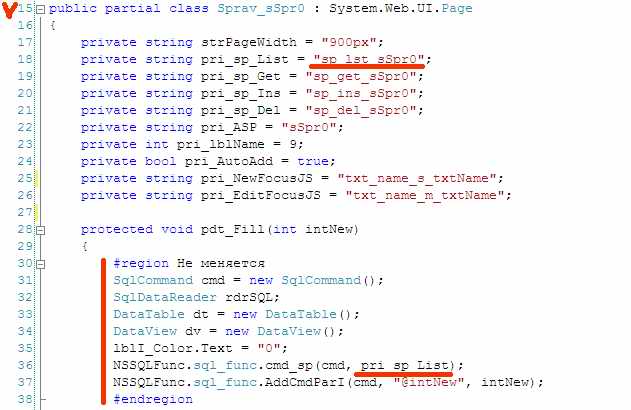
Это самое начало файла, т. е с 15-й строки. Тут прямо наверх вынесены названиях хранимых процедур, которые тут используются. Их четыре по тем самым основным действиям, которые всегда делаются с информацией. Всегда надо выводить на экран список строк. Этим тут занимается процедура sp_lst_sStr0. Мне не надо рыть текст в поисках места, где надо ввести эту строку. Название засунуто в переменную pri_sp_List и имя переменной уже засунуто в текст процедуры, выводящей список (pdt_Fill).
Текст, как уже сказано, адоптирован под штамповку. Обычно если надо что-то новое, то просто копируется старый текст и в нужных местах делаются изменения. Здесь мне в новом аналогичном тексте надо сверху поменять названия процедур, а дальше что-то поменять в тексте. Причём в тексте есть места, которые точно менять не надо. Их даже можно скрыть в редакторе, засунув между #region и #endregion.
Выглядит это так:

… Т.е просто скрыто то, что никогда не меняется. Я быстро просматриваю весь текст и вношу изменения только там где они нужны. У хранимой процедуры осуществляющий выборку строк, например, могут быть самые разные параметры, ограничивающие список строк.
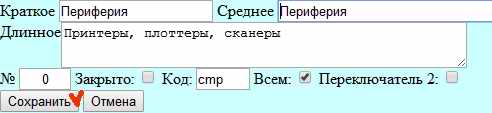
Пусть я не знаю, какая хранимая процедура вызывается при сохранении информации. Единственное, что я знаю точно это то, что это сохранение тут есть. Могу предположить, что чтобы что-то сохранить используется какая-то кнопка.
При выполнении я вижу эту кнопку и то, что на ней написано «Сохранить»:
Тогда я просто ищу это слово в ASPX файле по Ctrl+F:
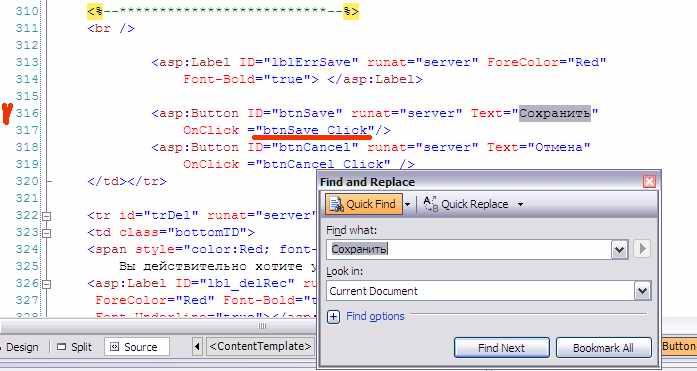
.. и мгновенно нахожу нужную кнопку вместе с названием обработчика нажатия этой кнопки (btnSave_Click) несмотря на то, что это всё довольно далеко, на 316-й строке текста.
Вот он этот btnSave_Click:

… вызывающий функцию которая уже обращается к базе. Далее хоть поискам хоть переходом к определению функции в контекстом меню редактора:
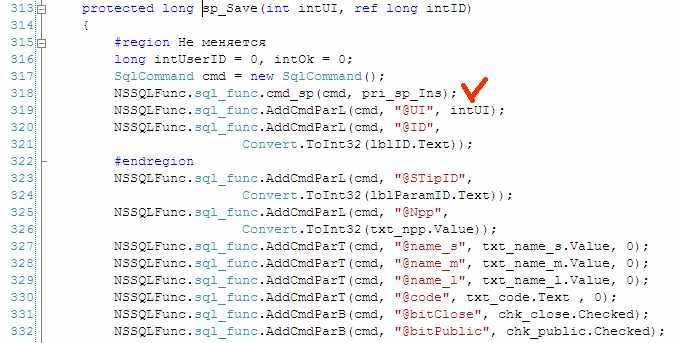
… а нахожу имя той процедуры которая у меня обращается к базе.
На самом деле это даже так редко делается. Есть так называемый ОТЛАДЧИК, который позволяет вызвать тексты прямо в момент выполнения программ, благополучно добраться до интересующей информации и узнать как конкретно тут что-то называется.
Это общий метод. Я знаю, что у меня тут все кнопки сохранения называются btnSave, но если это не так я найду точное название за несколько шагов потеряв секунды.
Названия и всевозможные префиксы нужны чтобы сортировать информацию в списках при не основном но часто нужном просмотре глазами.
Например если я в редакторе ввожу вообще любую букву:
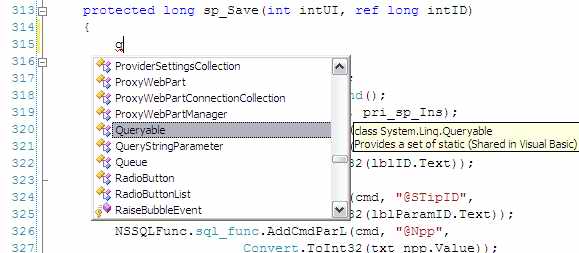
… он мне сразу показывает список со словами, которые начинаются на эту букву и могут мне понадобиться.
Все общие для текста переменные у меня имеют префикс pri. Вот я их всех в списке и увижу, введя буквы «pri»:
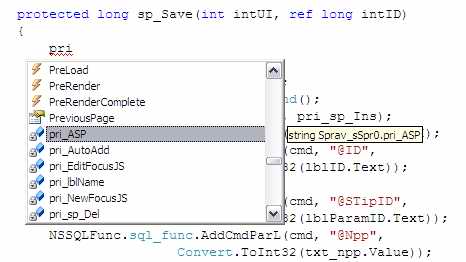
Написание полного названия происходит очень редко. И не помнит никто всех названий и ошибиться в буквах можно. Потому обычно вводятся первые буквы, а остальное выбирается из списка.
Тоже самое делают все оболочки. Вот, например, SQL Server предлагает мне список таблиц текущей базы данных:
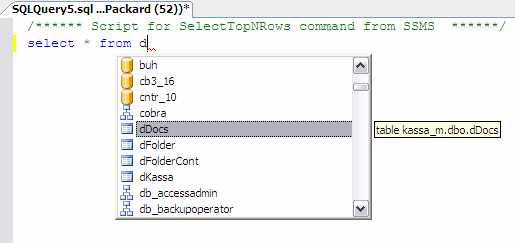
Точно также он может предложить хранимую процедуру для исполнения:

… Если у меня процедур с таким префиксом не много то и по остатку названия можно угадать, что мне нужно из этого списка. Но это такой лениво-ненадёжный случай для общения с хорошо знакомой и обычно своей программой. Обычно же общаться приходится с чужим или своим но старым, т.е полный поиск точной информации присутствует. Но с названиями хоть как-то намекающими на то, что там внутри всё-таки проще потому кто-то типа «nakl», «Tovar» обычно пишут.
Иногда пишут длинные названия. В английских текстах редко, потому что английского никто не знает, а если кто и знает, то писать он может только для себя, что не имеет смысла. А в 1С где названия русские и тоже все выбирается из подсказок в списке что-то типа НакладныеНаОтгрузкуПродукции даже рекомендуется хотя по-моему это неудобно. Там есть дополнительный повод так писать. 1С автоматически при создании берёт эту информацию, вставляет пробелы и делает названием формы на экране: «Накладные на отгрузку продукции».
Вот как это у них выглядит:

А при вводе это так выглядит:

… т.е по точке после «Документы» выпал список. Названия длинные, но полное название текущего элемента подсвечивается. Все эти буквы вводить не надо, достаточно выбрать нужное и оно само нарисуется. С моей точки зрения такое длинное неудобно читать, но я не могу сказать, что это особо мешает. И так можно если у них так принято и они всё делают чтобы это нигде не мешало.
|




