Языки программирования – 6
В своё время я написала, что компьютер – не человек. Сегодня попытаюсь показать то, что получает вводимую человеком, например, строку поиска и что-то с ней делает.
Пример будет на Borland С++. Из этого не следует, что я считаю, что писать надо именно на этом. Просто здесь лучше всего видно, что там внутри происходит. Пример выдернут из реальной программы. Надеюсь, что ничего лишнего я не стёрла, но работоспособность мне проверять не на чем (не тот повод чтобы ставить компилятор от Borland-а).
Если скопилировать тексты, то получится файл с расширением CGI. На компьютере, на котором находится сайт, к которому по адресу обращаются все желающие установлена программа которая получает запрос от пользователя (IIS, Apache и т.д.). Пользователь, например, зашёл на www.google.com и написал там в строке поиска «gps класс msdn». Та программа и получит во-первых адрес «www.google.com» во-вторых введённую подстроку ««gps класс msdn». Сама эта программа не имеет ни малейшего представления как надо на это реагировать. Но она может запросить информацию в файле CGI передав ей всё полученное в виде параметров (примерно также как вызов функции с параметрами).
В примере будет получение и проверка пароля.
Окно в котором надо ввести пароль, чтобы войти в информацию сайта выглядит примерно так:
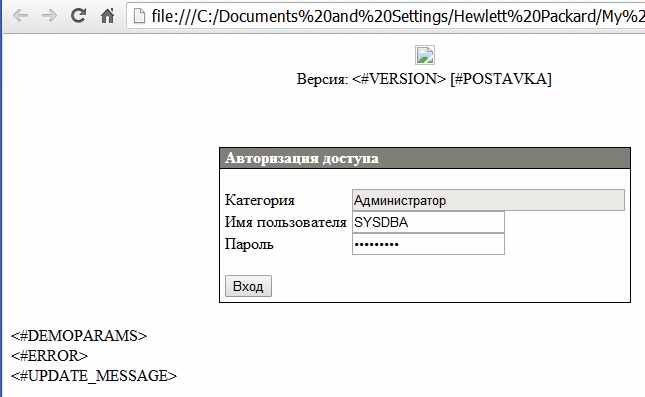
Окно выгладит довольно странно. Есть несколько полей, начинающихся с «#», например «#VERSION». Дело в том, что просматриваемый тут файл login.htm только заготовка информации, которая будет отправлена пользователю. Перед отправкой в содержимом текстового файла login.htm подстрока «#VERSION» будет заменена на номер версии.
Любой браузер, т.е программа просмотра Интернетовских страниц получает текст, интерпретирует его и рисует то, что должно быть нарисовано.
Текст запроса пароля:
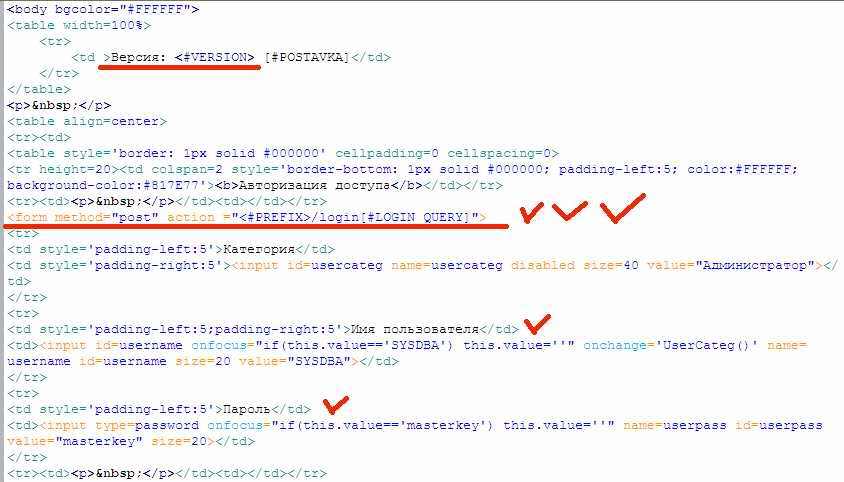
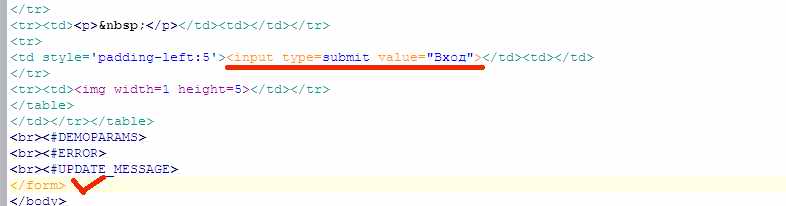
Каракули, естественно, довольно страшные, но браузер их успешно читает и рисует на экране окно с запросом имени пользователя и пароля.
Обращаю внимание на то, что запрос происходит внутри ТЭГа <form>. Тэги это текстовое описание элемента, которое читает браузер. Form означает «форма», т.е что-то типа окна Widows, т.е нечто логически цельное. Кроме того написано, что у этой формы метод (method) = post (т.е отправка), а в странице, которая будет запрошена после отправки написано ?action ="<#PREFIX>/login[#LOGIN_QUERY]", т.е тут ещё несколько подстрок, которые (как и номер версии) будут заменены на реальное содержание.
Теперь текст (который будет преобразован в CGI файл), который обрабатывает то, что пользователь вошёл на сайт и запросил страницу имя_сайта\login.htm.
Как и полагается программе на С++ начинается она с подключения библиотек функций и определения глобальных переменных:
#include <stdlib.h>
#include <iostream>
WebModule *wm;
Request *request;
Response *response;
PageProducer *pp;
map<string, string> tags; // всякие тэги тут
… Библиотек на самом деле больше, а вот переменные Response и Request важны. Response это буквально то, что будет передано пользователю. Т.е вошёл пользователь, запросил страницу. То, что ему вернут и есть Response.
int main () {
// Create common objects
pp = new PageProducer ();
pp->OnHTMLTag = ppOnHTMLTag;
request = new Request ();
response = new Response ();
ReadIniFile ();
response->prefix = tags ["PREFIX"];
CreateResponse ();
}
Выполнение любой программы на Си начинается с функции main(). Функция main() что-то сделала, а потом передала управление тому, что будет создавать Response для пользователя. Функция и называется CreateResponse ():
void CreateResponse () {
if (request->path == "/LOGIN" || request->path == "") {
wm->waLogin ();
else if (request->path == "/UCH") wmUch->waUch ();
else if (request->path == "/SPR") wm->waSpr ();
else if (request->path == "/SPR_SAVE") wm->waSprSave ();
else if (request->path == "/EDIT") wm->waEdit ();
else if (request->path == "/TABLE_SAVE") wm->waTableSave ();
..... много, много, много названий страниц…..
}
Функция CreateResponse() тоже ничего не создаёт а передаёт управление функции wm->waLogin ();
void WebModule::waLogin()
{
tags ["LOGIN_QUERY"] = "?check=1";
if (request->queryFields ["CHECK"] == "1")
{
request->contentFields ["USERNAME"] = Upper (request->contentFields ["USERNAME"]);
response->cookieFields["USERNAME"] = request->contentFields ["USERNAME"];
response->cookieFields["USERPASS"] = request->contentFields ["USERPASS"];
request->cookieFields["USERNAME"] = request->contentFields ["USERNAME"];
request->cookieFields["USERPASS"] = request->contentFields ["USERPASS"];
RestoreUser(); // если ошибка, то функция сама сообщит пользователю
waWelcome ();
return;
}
pp->HTMLFile = tags["HTML"] + "/login.htm";
response->content = pp->Content();
}
Я тут несколько упростила и предполагаю, что пользователь никогда не ошибается с вводом паролей.
Напомню, что в html заготовке login.htm в обработке кнопки «Вход» было написано так: “action ="<#PREFIX>/login[#LOGIN_QUERY]", т.е по этой кнопке управление будет передано тому же login.html (будет вызвана та же страница), но с параметром #LOGIN_QUERY, какой написан. Но при первом входе на страницу в неё нет никаких параметров. Просто написано : “имя_сайта\login”.
Вторая определённая глобальная переменная Request. По нажатию кнопки «Вход» не только запрашивается следующая страница, которая должна быть передана в виде следующего Response, но и передаются введённые пользователем значения всех текстовых полей, которые есть на этой странице. Это всё, полученное от пользователя и находится в объекте Request. Но ещё в нем есть список параметров, с которыми вызывалась страница. Т.е если было вызвано «имя сайта\login\?check=1”, то в коллекции request->queryFields появится элемент request->queryFields ["CHECK"] равный единице. Но при первом вызове никаких параметров нет. Потому поменяв версию и прочее на считанное из INI файла управление обходит if и проваливается до последних двух строк. Там пользователю отправляется login.htm для ввода информации. А вот после нажатия кнопки «Вход» при повторном запросе страницы параметр check будет уже равен 1 и начнётся какая-то обработка информации возвращённой через Request (например request->contentFields ["USERNAME"];). Информация текстовых полей находится в коллекции contentFields объекта Request.
Проверка полученного пользователя и пароля осуществляется функцией RestoreUser();. Здесь программа лезет в расположенный на компьютере сайта список паролей и сравнивает введённое с нужным. Поисковый сайт лезет в базу данных с содержанием страниц, роется в ней и вытаскивает все страницы, а которых есть эти слова. В этом примере после ввода пароля идёт переход на страницу приветствия waWelcome ();. После неё написано «return», т.е выход из функции waLogin, которая при наличии пароля никаких Response создавать уже не будет.
Работа в Интернете сильно отличается от работы программы на своём компьютере. Тут есть целых два компьютера, осуществляющих взаимодействие. Компьютер, на котором расположен сайт и хранится нужная информация – СЕРВЕР. Компьютер, с которого пытаются получить информацию, т.е любой компьютер, на котором гуляют по Интернету – КЛИЕНТ (по отношению к сайтам).
Взаимодействие – обычная практика. Компьютер и мышь тоже взаимодействуют. Существует набор договорённостей о том, как передаётся информация. В Интернете стандартом взаимодействия являются HTML тэги, определяющие что пользователь увидит на странице полученной из Интернета. Общие правила знают и владельцы сайтов и те, кто пишут браузеры для просмотра страниц.
В примере показано как осуществляется это взаимодействие. Пользователь постоянно запрашивает следующую страницу, постоянно же отсылая то, что он ввёл в текстовых полях на предыдущей странице. Эта информация обрабатывается и пользователю посылаются содержание следующей страницы.
Но у описанного метода есть хотя бы один очень серьёзный недостаток – полная перерисовка страницы Ведь каждый раз присылается новое содержание, причём полностью. Вторая проблема – скорость передачи информации между компьютерами. Обращение к любому адресу оперативной памяти своего компьютера занимает доли секунды, потому всё, что находится на своём компьютере доступно мгновенно (утрирую и упрощаю, но не сильно). Информация же с другого компьютера считывается по узкому (относительно своих данных) каналу информации потому доходит до подсчета байт, которые приходится гонять туда сюда (от сервера к клиенту и обратно).
Изначально Интернет не планировался для удалённой работы и прочего активного взаимодействия. Его создавали чтобы магазин мог написать на главной странице свои адрес и телефон. Самое большее чтобы пользователь мог ввести название товара и получить его цену из хранящегося на машине сайта списка товаров.
Но запросы пользователей начали расти. А базовый формат взаимодействия через Response, Request и реакции на них не очень на это рассчитан. Есть разные пути обхода этой проблемы (более или менее тяжёлые для памяти и трудоёмкие для написания), но красивого решения типа того, чем было объектно-ориентированное программирование при переходе от DOS к WINDOS пока не возникло. Скорее в совсем обходные вещи процесс пошёл а не в развитие базового протокола.
|




