Расположение информации в базах данных и SQL строки
База данных это несколько таблиц с информацией. Таблица это буквально таблица, т.е нечто, в которое информация записывается строка за строкой. Пусть, например, есть два документа – платёжное поручение и какая-нибудь накладная. И там и там есть название организации – контрагента. Оно довольно длинное, т.е при примитивном хранении данных каждая строка таблиц с накладными или платёжками будет содержать как минимум это название длиной букв 20-50. Размер базы при таком варианте - не единственная проблема. Это всё трудно искать, ещё сложнее менять если вдруг потребуется. Ошиблись, например, и весь день вбивали название с ошибкой. Потом придётся везде найти и исправить.
Решением являются так называемые идентификаторы – ID. Это ничего не значащие номера строк таблиц – справочников, в которых содержится полная информация о неком объекте (например, о той самой организации – контрагенте). Название хранится только в справочнике, а в накладных и платёжках хранится ID нужной организации. Название и любая другая информация справочника вытаскивается по связи через этот ID.
Упрощая жизнь пользователю, эта штука усложняет жизнь программисту. Потому уже во времена DOS-а к базам на основе dBase была прикручена некоторая автоматизация для работы с этими связями. В любом случае машине надо как-то объяснить, что когда она видит ID, она должна показать наименование, ИНН или телефон этой организации. Самой же машине для этого надо залезть в таблицу – справочник, найти строку с нужным ID и забрать из той строки наименование или ещё что-то.
SQL – строка это запрос машине на выборку информации. В ней всё максимально удалено от метода добывания информации, потому не возьмусь утверждать что текст может быть интуитивно понят. Но как правило эти строки никто и не читает. Их сразу засовывают в конструктор, где хорошо видно что с чем связано и что откуда взято.
Вот немного упрощённый вариант выборки списка платёжек на расход:
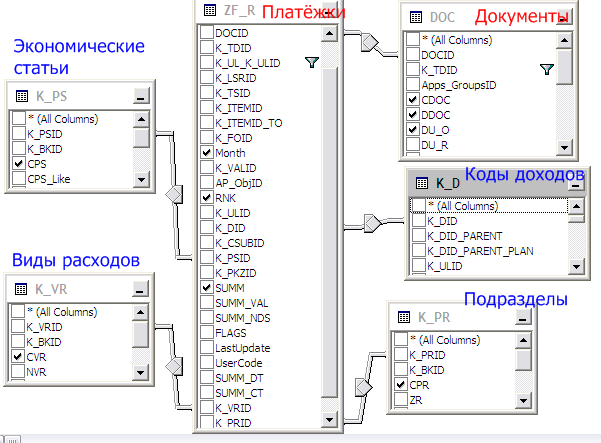
Таблицы документов – красные, справочники (называемые тут классификаторами, потому названия начинаются с «K_») – синие.
В таблице платёжек хранится, например, ID подраздела K_PRID. Если требуется код или наименование надо взять его по связи с таблицей подразделов K_PR.
А в отдельной общей таблице документов DOC хранится большая коллекция дат (утверждения, распорядителя и т.д). Поскольку платёжки обычно интересуют за период, надо привязать и эту таблицу по ID документа DocID.
В названиях тут обычная смесь «французского с нижегородским». Поле «код вида доходов» в таблице K_VR называется CVR, где «С» от «code», VR это «вид расходов».
А так выглядит SQL строка того, что на картинке, которую обычно никто не читает:
SELECT dbo.DOC.DDOC AS DOC_DDOC, dbo.DOC.DU_O AS DOC_DU_O, dbo.DOC.CDOC AS DOC_CDOC, dbo.ZF_R.SUMM, dbo.ZF_R.RNK,
dbo.ZF_R.Month, dbo.K_PS.CPS, dbo.K_PR.CPR, dbo.K_VR.CVR, dbo.K_D.CDS
FROM dbo.ZF_R LEFT OUTER JOIN
dbo.K_D ON dbo.ZF_R.K_DID = dbo.K_D.K_DID LEFT OUTER JOIN
dbo.K_VR ON dbo.ZF_R.K_VRID = dbo.K_VR.K_VRID LEFT OUTER JOIN
dbo.K_PR ON dbo.ZF_R.K_PRID = dbo.K_PR.K_PRID LEFT OUTER JOIN
dbo.K_PS ON dbo.ZF_R.K_PSID = dbo.K_PS.K_PSID LEFT OUTER JOIN
dbo.DOC ON dbo.ZF_R.DOCID = dbo.DOC.DOCID
После «SELECT» перечисление полей, которые я хочу получить. В списке обычно вначале «dbo», потом имя таблицы, из которой берется информация и потом название поля.
После FROM – перечисление таблиц и связей между ними (после ON – по каким полям связь).
Выборка по платёжкам из ZF_R:
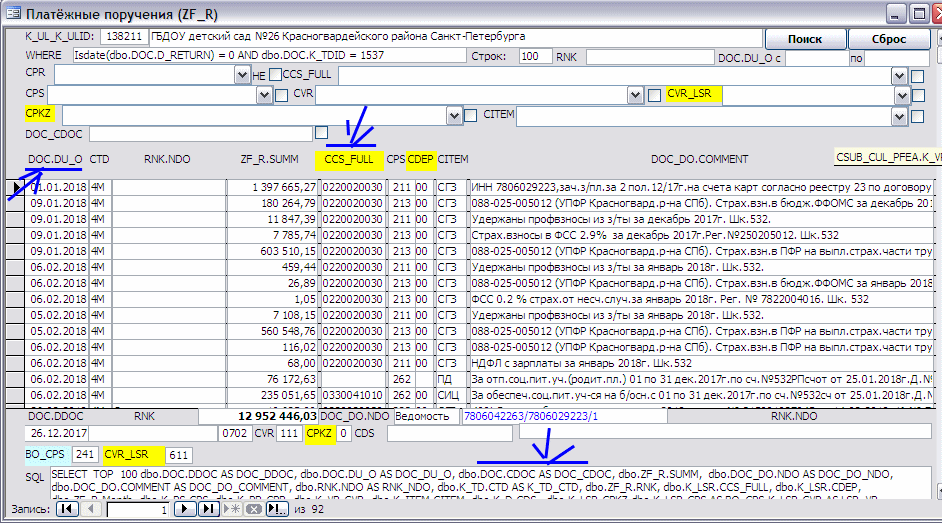
… с именами полей таблиц базы данных вместо обычных названий.
Во-первых, можно написать откуда бралась информация, например, одна из дат (та, по которой осуществляется задание периода) написана как DOC.DU_O. А в платёжках на приход ориентировка по ZF_D.DBN (т.е дата хранится в таблице документа).
Во-вторых, жёлтым у меня выделена информация берущаяся из другой таблицы. Целевая статья (CCS_FULL) берётся через справочник счетов расходов. Не важно что это, важно что меня интересует структура базы, с которой я работаю и я её сразу вижу.
В-третьих, внизу в меня SQL строка выборки информации. Я её могу отсюда взять, перенести через буфер в сервер, увидеть на схеме как что перевязано и при необходимости что-то добавить.
В верхней части формы у меня поля для фильтрации и две кнопки. «Поиск» - выбрать то, что найдётся по фильтрам, «Сброс» - сброс фильтров в исходное состояние.
В SQL-строке есть ещё выражение WHERE задающее фильтры. Обработчик кнопки «Поиск» генерирует SQL строку по заданным фильтрам:

Вначале какой-то SELECT, потом какой-то FROM. Первый фильтр для WHERE это ID учреждения. А все остальное добавляется если пользователь что-то написал в этом фильтре:

Если что-то выбрано в подразделе (cmbPR) то проверяется есть ли галка («НЕ») справа от поля со списком. Если её нет (chkPR.value=false), то выбирать надо по выбранному подразделу (K_PRID=выбранное значение). Если же она есть, что выбрать надо все строки, где что-то другое (чтобы, например, увидеть всё необычное убрав самое частое). В этом случае в WHERE добавляется K_PRID<>выбранное значение.
Ниже там вот так:
strSQL = strSQL & strFrom & strWhere
Me.RecordSource = strSQL
… т.е SQL строка собирается вместе и присваивается источнику записей формы. Так что всё весьма примитивно.
Надо написать про то, что сделано в «Казначействе». Там к таблице, например к всё той же ZF_R прицеплено всё, что только можно и у пользователя есть возможность и выбрать что угодно из этого набора и фильтры поставить на любое поле. Это OLAP-куб, по -умному. К ним всё постепенно подбираются, СКД отчеты в 1С это тоже возможность навыбирать что угодно и как угодно изобразить данные какой-то общей собранной с разных таблиц таблицы.
У меня тут такого нет. И если мне вдруг потребуется посмотреть что-то необычное я перекину SQL строку в сервер и посмотрю вначале там. Т.е гибкость обеспечивается не клиентским приложением и возможностью перейти в сервер и там получить ещё больше гибкости при выборке (больше чем там не бывает))) ).
С другой стороны, всё чего мне надо вроде бы есть и кнопок на экране всего две, т.е для обычной ситуации всё максимально быстро и просто. И в списках выводятся только те строки, которые есть для этого учреждения:
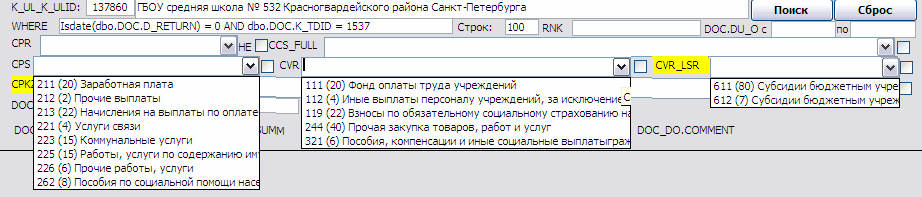
… (в скобках количество таких строк). Это тоже для скорости. Видны только нужные и сразу видно часто это или экзотика. Это всё – мелкие удобства за которые приходится расплачиваться чуть меньшей гибкостью. Теоретически и в казначейских фильтрах можно ограничивать списки. Например если выбран лицевой счёт, то можно также ограничить списки экономических статьей и прочего. Но делать это там при изначально выбранном уровне гибкости было бы очень сложно. А я себе на коленке сделала нечто технически примитивное, к чему это прицепить можно.
А если мне чего-то не хватит, а переключусь в SQL-сервер. На то и Windows чтобы несколько окон на экране было))).
Надо ещё добавить, что Access изначально делался как инструмент опытного пользователя а не программиста, т.е его делали чтобы люди себе сами делали маленькие базы, типа «Курсов валют», сооруженных офисной секретаршей. Там всё просто.
А SQL-строки отсюда можно перенести в любого другого клиента через всё тот же буфер. Про это, что это всё обычно отличается наличием или отсутствием точек с запятой было, например, тут:
http://akostina76.ucoz.ru/blog/2016-10-13-3513
Сложнее, конечно. Но SQL строки точно одни и те же и их можно просто копировать.
|




