Распределенная база данных
Про такие базы тут:
http://citforum.ru/database/classics/distr_and_paral_sdb/
Отсюда:
http://expert.ru/2016/10/26/merkel-potrebovala-ot-facebook-i-google-predostavit-algoritmyi/
Канцлер Германии Ангела Меркель заявила в четверг, что интернет-гиганты Google и Facebook должны раскрыть алгоритмы выдачи результатов поисковых запросов и отображения постов в ленте пользователя. По ее словам, это нужно, чтобы избежать манипуляций, политических провокаций и дестабилизации в странах ЕС.
Отсюда:
http://inosmi.ru/politic/20160105/234973004.html
Появление интернета — это становится все заметнее — фундаментально изменило современный мир. Люди не просто получают информацию, глядя на экран, а не на бумагу. Это делает получаемую информацию еще непосредственнее и эмоциональнее, однако, весь процесс менее связан с рефлексией.
— Не могли бы вы поточнее описать влияние интернета на внешнюю политику?
— В интернете можно снова и снова кликать на один и тот же ответ, так что теперь стало меньше стимулов разделять события в мире на различные категории и выводить различные концепции. Большое количество фактов зачастую мешает анализировать их. Кроме того, у политических лидеров теперь есть намного больше поводов реагировать на настроение общества в моменте.
Вообще-то всё просто.
Вот типовая SQL строка по поиску слова «отчёт» в поле с текстовой информацией:
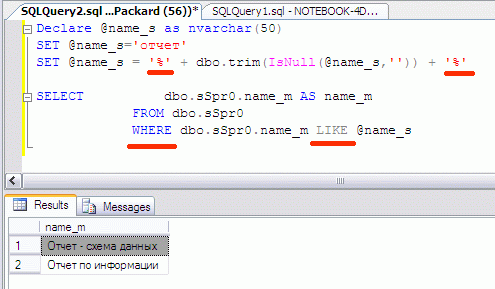
Здесь подстрока поиска засунута между знаками «%», что означает, что до и после неё может быть что угодно. А потом всё вместе передано условию WHERE в выражение LIKE, что означает «содержится в строке». Здесь у меня поиск в наименовании, но в поле базы данных может быть записан весь HTML текст страницы.
Если мне надо найти страницы, в которых есть сразу несколько слов, то будет записано так:
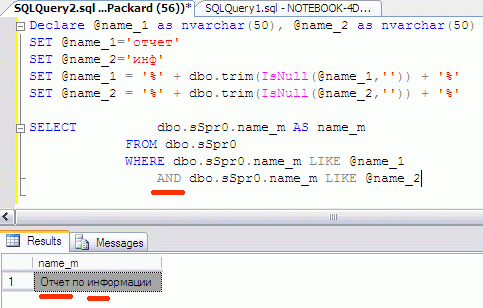
Если слов больше, то и ANDов в SQL строке будет больше. Чтобы ускорить процесс могут быть созданы специальные полнотекстовые индексы, но это уже внутренняя работа сервера. Страниц, в которых есть любые два слова естественно в Интернете очень много, потому логично выбрать им такой порядок, чтобы наверх попадали те страницы, которые скорее всего нужны пользователю. Точнее, в теории это должно быть так. Наиболее естественно вытащить наверх те страницы, в которых эти слова встречаются в заголовках, благо это не сложно. В формате HTML документа заголовками находятся между тэгами заголовков. Можно поднять ещё выше те страницы, в которых слова находятся последовательно даже если пользователь не указал точную последовательность, засунув строку в двойные кавычки. То, что в сортировке строк поднимает вверх или опускает вниз найденную информацию обычно называется весовым коэффициентом, который заполняется по какому-то алгоритму.
И здесь (в формировании этого коэффициента) полная свобода. Можно хоть в тексте выборки присвоить вес в 1 миллиард всем страницам какого-то сайта и тогда эту информацию никогда не найдут, т. к она утонет в прочих строках. Это, конечно, странно делать, жёстко вставляя имена сайтов в текст. Обычно формируются списки и настройки типа этого файла:
robots.txt
… которые уже и обрабатываются поисковиками. Точно также, подозреваю, можно поднимать вверх какие-то строки, уменьшая весовой коэффициент, если найдена страница, не из «черного», а из «белого» списка. Ходили слухи о том, что это напрямую платная услуга, но точно я это не знаю.
Кроме платных услуг существуют скорее всего и реальные технические проблемы. Я плохо себе представляю базу данных даже крупной организации за несколько лет, которая может всерьёз нагрузить SQL Server. Конечно, база должна быть грамотно написана, но всё-таки. А вот поисковики вынуждены обрабатывать такие объемы причём неструктурированной информации, которые я себе и представить не могу. Я сильно сомневаюсь, что существуют жесткие диски, на которые может поместится вся информация Интернета. Это означает, что нужно несколько компьютеров, на которых просто хранится информация в которой надо что-то искать.
Здесь:
http://akostina76.ucoz.ru/blog/2016-10-11-3507
… показано как происходит обращение к информации других серверов (т.е других компьютеров). Поисковик скорее всего делает как-то не так, но суть та же. Для того, в числе прочего, и создавались возможности работать сразу с несколькими серверами чтобы при больших объемах данных можно было их разложить по нескольким компьютерам.
Но и этого мало. Пользователей много, а сервер это машина, которая должна выполнять какие-то действия, т.е конкретно искать информацию. Чем больше пользователей запросили информацию, тем медленнее он будет работать. Это означает, что логично дублировать данные, т.е ещё удваивать, утраивать количество компьютеров и посылать запрос на выборку наименее загруженному. Это всё и называется «распредёлённая база данных» с которой приходится работать когда всего слишком много.
Но всех этих технологий, видимо недостаточно для хранения действительно всего, что есть в Интернете. Ещё раз повторюсь, что я даже приблизительно не представляю, сколько это всё может занимать. Подозреваю, что есть ещё проблема скорости. Пользователь не поймёт, если ему список будет выводится через 5 минут. Точнее на такое массовый пользователь будет постоянно жаловаться. А если список урезать, то 99 и 9 в периоде процентов этого просто не заметят, а малая доля тех, кто заметит слишком мала чтобы кричать по этому поводу слишком громко.
Так или иначе, базы поиска точно срезаются. Подозреваю, что из них пропадают давно не запрашиваемые страницы, например. Часто сложно найти старую информацию, которая легко находилась лет 5 назад. Как происходит это удаление из базы тоже неплохо бы выяснить.
Ещё есть механизмы, позволяющие создать искусственную популярность. Т.е на страницу заходят специальные программы, а результат не отличается от того, что было бы если бы приходили настоящие люди. Насколько понимаю, там, где дело касается денег, например, рекламных этим затоплено всё. Логично предположить, что в политике не только те же технологии, но и те же люди торгуют услугами по созданию искусственной популярности темы и мнения.
Попросту говоря, по моим ощущениям, нельзя ориентироваться по Интернету при таких масштабах приписок. В основе этого Интернет – жульничества лежит, например, особо вдохновляющий всех этих проходимцев опыт Кортеса, который воспользовался тем, что покоряемые им инки имели специфическую религию, т.е картину мира, которая и помогла испанцам. Если кто-то думает, что информация в Интернете, или в социологических опросах отражает мнение существенной части общества, то это ещё один вариант иллюзии и это надо использовать. Вот они и используют.
Осенью прошлого года на меня произвели впечатление синхронные странности FaceBook и YouTube. Чем бы они ни были вызваны, это уже не жульничество с фальшивыми просмотрами а вход с парадного входа, т.е через руководство конторой, потому интерес именно к поставщикам услуг (Google, FaceBook) уместен.
|




