Дополнение по отчётам
Т.е к этому:
https://akostina76.ucoz.ru/blog/2019-07-18-5943
Улучшить печать довольно просто и проще это сделать со стороны программы. Чтобы итоги точно выводились под данным надо считать всю следующую за итогами партию данных, посчитать сколько места на листе это займёт (вместе с итогами) и начать печать следующей страницы если места не хватает. У меня же эта проверка делается после печати каждой строки. Этим и вызван возможный разрыв информации в неподходящем месте.
Проблема в том, что в любом случае (надо или не надо начинать новую страницу) надо вернуться к началу нового куска данных и начать его печатать.
В начале каждого программного текста перечисляются все механизмы, которые в нем используются:

При печати бумажек у меня подключаются два вида работы с данными. Linq – это новое, которое только что появилось. SqlClient – это предыдущий стандартный набор инструментов для работы с базами данных (ADO.NET).
Отчёты я переписывала, меняя запетые. Потому в них оставлен старый метод обращения к дынным. (Linq мне интересен в первую очередь как механизм корректировки информации).
Вот как он выглядел:
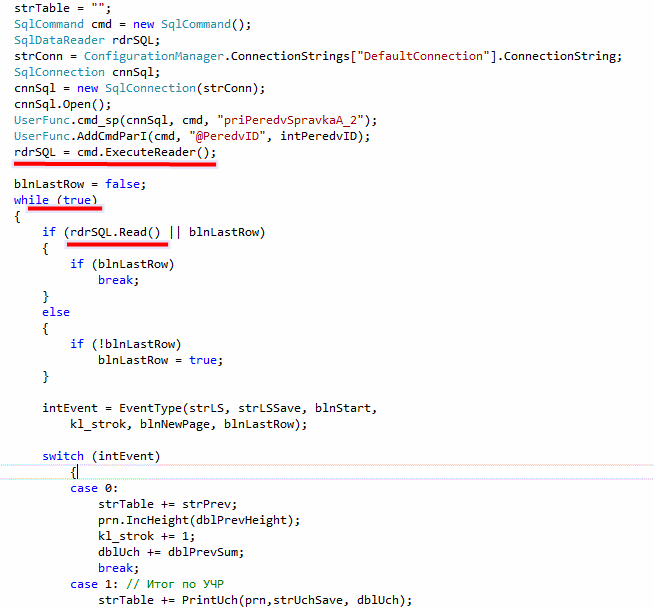
Данные из базы считывались в так называемый Reader. А из него уже информация вынималась строка за строкой. Выход из бесконечного цикла по условию rdrSQL.Read()=False, т.е данные закончились и больше ничего не невозможно прочитать. Ни прыгнуть в конец таблицы с данными ни вернуться в начало я в этом reader-е не могу. Если мне это очень надо, то я могу вначале всё это прочитать и скопировать в созданный массив информации, а потом ходить по строкам этого массива как угодно. Так можно было сделать, но я решила, что лучшее – враг хорошего.
А вот как идёт работа с информацией в Linq:

Вначале хитрым способом формируется строка запроса информации, а потом информация всегда вытаскивается в так называемый список. В данном случае разновидность списка – IPageList. Чаще это просто IList. Html-странице, кстати, тоже передаётся именно список (return View(lst)).
Этот список по сути - тот же массив. В нем обращение к строкам по их номерам. Прыгать можно в любой момент куда угодно. Так что этой проблемы нет вообще.
Ещё раньше, что интересно, её тоже не было. В ADODB был не Reader а Recordset:

По нему можно было перемещаться не только вперёд (MoveNext), но и назад (MoveRevious), в начало или в конец.
Работа с Reader-ами урезана по возможностям до предела. Отчасти это, скорее всего, вызвано пиком полупринудительного перевода всех на работу через хранимые процедуры. Нечего делать что-то в клиентских текстах. Всё в базе надо делать. Надо отдать должное, перекрыть возможности им всеми этими ограничениями удалось. Там, например, просто нельзя одновременно открыть два Reader-а.
А теперь опять всё поменялось. И стандартным инструментом – хранилищем данных стал даже не Recordset, движение по которому всё-таки ограничены, а расширенный массив TList.
Надо, наверное, ещё добавить, что можно и лучше сделать, чем у меня было сделано. У меня, например, итоги по базе вручную (в клиентском тексте) считаются. А это потому, что в DOS-е вот так оно и делалось. А потом все делали сами конструкторы отчётов. А когда мне вдруг потребовалось что-то такое изобразить, нарисовался старый DOS-овский вариант.
Хотя вот это всё:
https://akostina76.ucoz.ru/blog/2018-08-14-5297
… на тот момент уже было. Так, наверное, проще. Сервер сам считает все итоги. Определить, что это итог можно по NULL-ам. В отчете надо просто брать полученные цифры (в т.ч суммы) и засовывать в HTML-таблицу.
|




