Медицинская база (ключевые слова)
Я уже писала, что судя по объему информации до ввода ключевых слов ещё далеко. Но ведь кроме того, что есть сейчас есть ещё и возможные направления развития. Если их не учитывать то можно наделать того, что помешает в будущем.
Эта обработка позволяет разбирать тексты на ключевые слова:
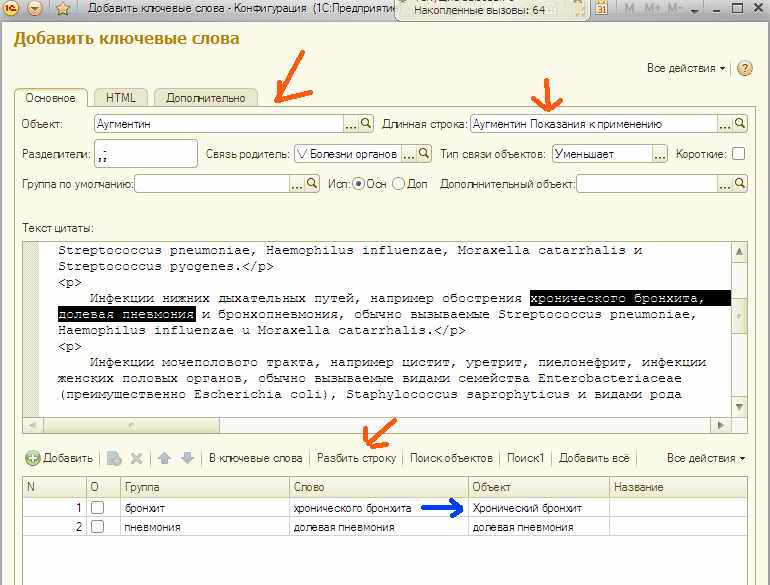
В данном случае требуется выдернуть из показаний к применению те болезни при которых используется препарат. Выделенная строка разобрана (через разделитель запатую) на две строки в списке. Но ещё надо найти в базе тот объект, который соответствует слову или группе слов. А падежи в текстах вовсе не обязаны быть именительными, и число не обязано быть единственным. В данном случае в тексте было «хронического бронхита» что не помешало найти правильное соответствие – «хронический бронхит». Дело в том что при поиске использовался ранее упомянутый полнотекстовый поиск.
К сожалению это решение потенциально не очень хорошее. Дело в том, что полнотекстовый поиск придумывали чтобы искать вообще по всей базе ничего не потеряв. Пусть кто-то когда-то куда-то прицепил справочник про который все забыли. Конфигурации бывают сложные и не всегда можно вспомнить что тут где лежит и зачем. А полнотекстовый поиск, работающий по всем данным не разбираясь проходит по всей информации. Ему нельзя указать места, где надо искать. А я его здесь использую чтобы вытащить названия из справочника объектов. Попросту говоря я вначале ищу везде а потом выбираю найденное в названиях.
Вообще-то вопрос только в быстродействии компьютера. Это же не я ищу а он. Пусть он хоть 5 минут что-то ищет, я же в это время буду отдыхать а не искать вручную те же соответствия.
Но всё равно это не очень хорошо потому, что с ростом базы данных ещё неизвестно во что выльются незаметные доли секунд поиска которые есть сейчас.
То, что можно быть сделать для ускорения поиска уже сделано. Полнотекстовый поиск запускается только если не найдено точного соответствия при обычном поиске и если не найдено точного соответствия в ранее введенных ключевых словах.
Ведь можно учитывать уже введённую в базу информацию и предполагать, что её количество будет только расти. Пусть я сейчас добавлю в ключевые слова соответствие слов «хронического бронхита» объекту «хронический бронхит». Пусть это было найдено медленным полнотекстовым поиском или даже руками введено. Но соответствие-то это уже хранится в базе. Я могу его использовать при выборке (не обращаясь к полнотекстовому поиску). Так и делается в надежде на то, что это механизм будет брать на себя (по мере наполнения базы) всё больше работы.
Но я всё равно не знаю, как это будет работать при реально больших объемах базы. Это станет известно только когда в базе появится информация.
Изначально не столько планировалось сколько допускалось что поиском удастся вытаскивать например из таких строк
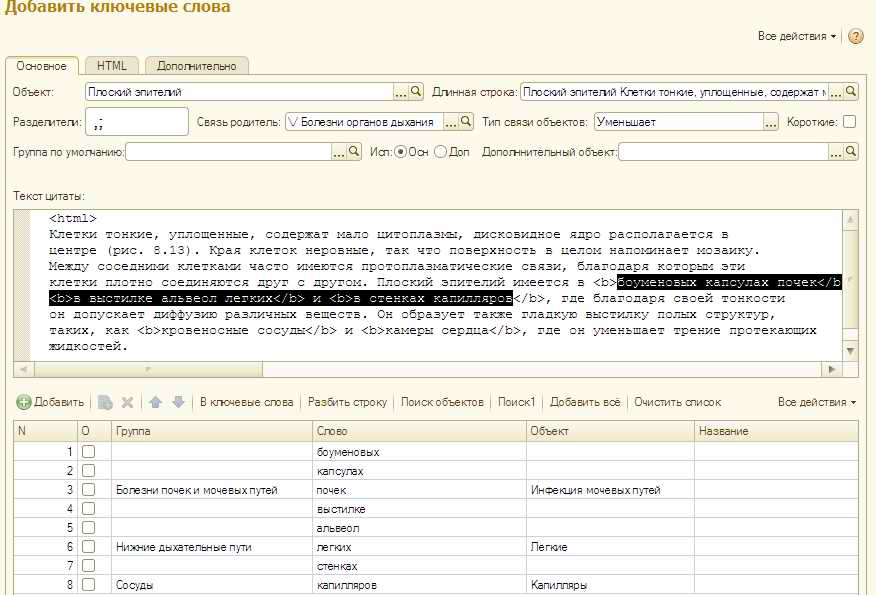
… все слова, которые уже введены в базу. Теоретически это уже сейчас можно делать. Я добавила в разделители пробел и запустила поиск. Чего действительно мне это всё читать? Пусть он сам прочитает и вытащит из текста те органы в которых находится этот плоский эпителий. Но не случайно для анализа выбран не весь абзац а его небольшой кусок. Моя, пусть не самая быстрая машина, довольно долго «жуёт» целый абзац. Что-то он даже нашёл, но часть с явной ошибкой вызванной той самой спецификой полнотекстового поиска.
Вот, например, что он нашёл для слова «почек»:

Это вовсе не то, что нужно. Эти строки он вытащил потому, что слово есть в «Родителе» (группе) этих объектов.

Всё это вместе означает что либо для ускорения поиска либо чтобы не было таких ошибок мне, возможно, придётся воспользоваться единственной его настройкой – отключением для части полей базы данных.
Это в свою очередь означает, что поиск может остаться только для длинных строк из справочника и названий объектов (в справочнике объектов). А из этого следует, например, то, что даже короткие строки типа таких:
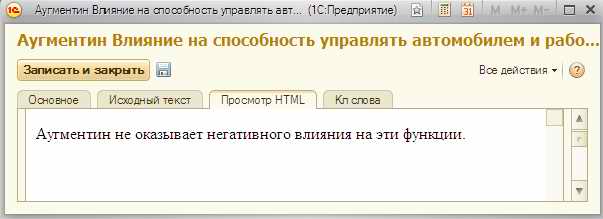
… лучше хранить в длинных строках хотя программа не запрещает завести под такое обычную строку а длина строки это позволяет. Но возможно сохранённая в таком виде информация станет недоступной для поиска.
Я не знаю как это будет развиваться дальше. Чтобы это понять надо ввести достаточно большой объем информации. Только тогда можно будет например сказать, где нужны ключевые слова а где хватает поиска по набору слов. Но я посчитала нужным показать, куда это может начать двигаться если потребуется всерьёз использовать полнотекстовый поиск при создании ключевых слов и связей из текстов.
Сюда:
https://drive.google.com/open?id=0B3i2SFYLER0HZEVFaVBrQVJVMDQ
… я положила новый вариант. В нем добавлены несколько текстов справочной информации. Не для всех вещей эти тексты добавлены, но этого думаю пока вполне достаточно. Список написанного в справке «Рабочего стола»:
Вот они все:

Так что кому интересно можно продолжить чтение например тут:

|




